45회 SQLD 시험 공부하면서 노션에 정리했던 글
- 데이터 모델의 이해
- 데이터 모델의 이해
- 데이터 모델과 성능
- SQL 기본 및 활용
- SQL 기본
- SQL 활용
- SQL 최적화 기본 원리
제 1장 데이터 모델의 이해
제 1절 데이터 모델의 이해
더보기
- 모델링의 이해
- 모델링의 정의 : “다양한 현상을 표기법에 의해 표기하는 것”
- 특징 : 추상화, 단순화, 명확화
- 모델링의 3가지 관점 : 데이터, 프로세스, 상관
- 데이터 모델링의 유의점
- 중복 : 데이터베이스가 여러 장소에 같은 정보를 저장하지 않게 함
- 비유연성 : 데이터정의를 데이터 사용 프로세스와 분리
- 비일관성 : 상호 연관 관계 대해서 명확하게 정의
- 생길 수 있는 문제 ex) 신용상태에 대한 갱신없이 고객의 납부이력정보 갱신
- 데이터 모델링의 3단계 진행
- 개념적 데이터 모델링 : 추상화 수준이 높고 업무 중심적이고 포괄적인 수준의 모델링
- 논리적 데이터 모델링 : 시스템으로 구축하고자 하는 업무에 대해 KEY, 속성, 관계 등을 정확하게 표현, 높은 재사용
- 물리적 데이터 모델링 : 실제로 데이터베이스에 이식할 수 있도록 성능, 저장 등 물리적인 성격 고려 설계
- 데이터베이스 3단계 구조 : 외부단계 / 개념적단계 / 내부적단계
- 데이터독립성 요소 : 외부스키마 / 개념스키마 / 내부스키마
- 데이터 모델링의 중요한 세가지 개념
- 데이터 모델링의 세가지 요소
- 업무가 관여하는 어떤 것(Things)
- 어떤 것이 가지는 성격(Attributes)
- 업무가 관여하는 어떤 것 간의 관계(Relationships)
- 단수와 집합(복수)의 명명
개념 복수 / 집합개념 & 타입 / 클래스 개별 / 단수개념 & 어커런스 / 인스턴트 Things Entity Type Entity Entity Instance / Occurrence Relationships Relationship Paring Attributes Attribute Attribute Value
- 데이터 모델링의 세가지 요소
- ERD 표기 순서
- 엔티티 그리기 → 엔티티 배치 → 엔티티 관계 설정 → 관계명 기술 → 관계의 참여도 기술 → 관계의 필수여부 기술
- 좋은 데이터 모델의 요소 : 완전성, 중복배제, 업무규칙, 데이터재사용, 의사소통, 통합성
제 2절 엔티티
더보기
- 엔티티의 개념 : “실체, 객체”
- 엔티티 특징
- 업무에서 필요로 하는 정보
- 식별자에 의해 식별이 가능 해야함
- 인스턴스의 집합
- 업무프로세스에 의해 이용
- 속성을 포함
- 관계의 존재
- 엔티티의 분류
- 유무형에 따른 분류 : 유형 엔티티(사원, 물품), 개념 엔티티(조직, 장소), 사건 엔티티(주문, 창구)
- 발생시점에 따른 분류 : 기본(키) 엔티티(사원, 부서), 중심 엔티티(접수, 계약), 행위 엔티티(주문 내역, 계약 진행)
- 기본 엔티티(키 엔티티) : 업무에 원래 존재하는 정보. 다른 엔티티와의 관계에 의해 생성되지 않고 독립적으로 생성이 가능. 자신은 타 엔티티의 부모 역할. 주 식별자를 상속받지 않고 자신의 고유한 주 식별자를 갖는다. ex) 사원, 부서, 고객, 상품, 자재
제 3절 속성
더보기
- 속성의 개념 : 업무에서 필요로하는 인스턴스로 관리하고자 하는 의미상 더이상 분리되지 않는 최소의 데이터 단위
- 엔티티, 인스턴스, 속성, 속성값의 관계
- 한 개의 엔티티는 두개 이상의 인스턴스의 집합이어야 한다.
- 한 개의 엔티티는 두개 이상의 속성을 갖는다.
- 한 개의 속성은 한 개의 속성값을 갖는다.
- 속성의 표기법 : IE 표기법, Barker 표기법
- 속성의 특징 : 하나의 속성에는 한 개의 값. 하나의 속성에 여러개의 값이 있는 다중값일 경우 별도의 엔티티를 이용하여 분리
- 속성의 분류
- 속성의 특성에 따른 분류
- 기본속성 : 사원 이름, 고용 일자, 직책 이름 등 가장 일반적인 속성
- 설계속성 : 업무상 필요한 데이터 외에 데이터 모델링을 위해, 업무를 규칙화하기 위해 속성을 새로 만들거나 변형하여 정의하는 속성
- 파생속성 : 데이터를 조회할 때 빠른 성능을 낼 수 있도록 하기 위해 원래 속성의 값을 계산하여 저장할 수 있도록 만든 속성
- 엔티티 구성방식에 따른 분류
- PK : 엔티티 식별할 수 있는 속성
- FK : 다른 엔티티와의 관계에서 포함된 속성
- 일반속성 : 엔티티에 포함되어있고, PK, FK가 아닌 속성
- 의미를 쪼갤 수 있는지에 따라 단순형, 복합형으로 분류할 수 있다.
- 속성의 특성에 따른 분류
- 도메인 : 각 속성이 가질 수 있는 값의 범위. 엔티티 내에서 속성에 대한 데이터타입과 크기 그리고 제약사항을 지정하는 것
제 4절 관계
더보기
- 관계의 개념
- 관계의 정의 : 엔티티의 인스턴스 사이의 논리적인 연관성으로서 존재의 형태로서나 행위로서 서로에게 연관성이 부여된 상태
- 관계의 페어링 : 페어링은 엔티티 안에 인스턴스가 개별적으로 관계를 가지는 것이고, 이것을 집합의 관계로 표현
- 관계의 분류
- ERD : 존재에 의한 관계 / 행위에 의한 관계
- UML(Unified Modeling Language) : 연관 관계 / 의존 관계
- 필수 / 선택 : Barker(실선 / 점선), IE( x, 동그라미)
- 식별자 상속 : Barker( | ), IE(실선)
- 관계의 표기법
- 관계명, 관계차수, 관계 선택 사양

- 관계의 정의 및 읽는 방법
- 두 개의 엔티티 사이에 관심있는 연관규칙이 존재하는가?
- 두 개의 엔티티 사이에 정보의 조합이 발생되는가?
- 업무 기술서, 장표에 관계 연결에 대한 규칙이 서술되어 있는가?
- 업무 기술서, 장표에 관계 연결을 가능하게 하는 동사(Verb)가 있는가?
제 5절 식별자
더보기
- 식별자 개념
- 하나의 엔티티에 구성되어있는 여러 개의 속성 중에 엔티티를 대표할 수 있는 속성을 의미
- 하나의 엔티티에는 반드시 하나의 유일한 식별자가 존재해야 한다.
- ⇒ 따라서 엔티티에는 반드시 하나 이상의 식별자가 존재하게 된다.
- 식별자의 특징 : 유일성, 최소성, 불변성, 존재성
- 식별자분류 및 표기법
- Barker : #
- 식별자 분류
분류 식별자 설명 대표성 여부 주식별자 엔티티 내에서 각 어커런스 구분. 타 엔티티와 참조 관계 연결 보조식별자 어커런스 구분. 대표성 x ⇒ 참조 관계 연결 x 스스로 생성 여부 내부식별자 엔티티 내부에서 스스로 만들어짐 외부식별자 타 엔티티와의 관계를 통해 타 엔티티로부터 받아옴 속성의 수 단일식별자 하나의 속성 복합식별자 둘 이상의 속성 대체 여부 본질식별자 업무에 의해 만들어짐 인조식별자 업무적으로 만들어지지 않지만 원조식별자가 복잡한 구성을 갖고있기 때문에 인위적으로 만듬 - 주식별자 도출기준
- 해당 업무에서 자주 이용되는 속성
- 명칭, 내역 등과 같이 이름으로 기술되는 것을 피한다.
- 속성의 수가 유일성을 갖는 최소의 수
- 주식별자가 지정되면 반드시 값이 들어와야 한다.
- 식별자관계 / 비식별자관계
- 식별자관계와 비식별자관계의 결정 : 외부식별자는 FK 역할
- 식별자관계 : 자식엔티티의 주식별자로 부모의 주식별자가 상속되는 경우. NULL값이 오면 안되므로 반드시 부모엔티티가 생성되어야 자기 자신의 엔티티 생성
- 비식별자관계 : 부모엔티티로부터 속성을 받았지만 자식엔티티의 주식별자로 사용하지 않고 일반적인 속성으로만 사용하는 경우
- 식별자관계로만 설정할 경우 문제점 : 주식별자 속성이 지속적으로 증가. 복잡성과 오류 가능성 유발
- 비식별자관계로만 설정할 경우 문제점 : 쓸데없이 부모엔티티까지 찾아가야 하는 경우 발생
- 부모엔티티의 인스턴스가 자식엔티티와 같이 소멸되는 경우 → 식별자 관계
- 부모엔티티의 주식별자를 자식, 손자까지 계속 흘려내기 위함 → 식별자 관계
제 2장 데이터 모델과 성능
제 1절 성능데이터모델링의 개요
더보기
- 성능모델링 : 데이터 베이스 성능 향상을 목적으로 설계단계의 데이터 모델링 때부터 성능과 관련된 사항이 데이터 모델링에 반영될 수 있도록 하는 것
- 성능 모델링의 절차
- 데이터 모델링을 할 때 정규화를 정확하게 수행
- 데이터 베이스 용량 산정
- 데이터 베이스에 발생되는 트랜잭션의 유형 파악
- 용량과 트랜잭션 유형에 따라 반정규화 수행
- 이력모델, PK/FK, 슈퍼/서브타입 조정 등을 수행
- 성능 관점에서 데이터 모델 검증
제 2절 정규화와 성능
더보기
- 정규화를 통한 성능향상전략
- 데이터에 대한 중복성을 제거한다.
- 일반적으로 정규화가 잘돼있으면 입력/수정/삭제의 성능이 향상되고, 반정규화를 많이하면 조회 성능이 향상된다.
- 중복 속성에 대한 분리가 1차 정규화의 정의. row 단위의 대상, column 단위로 중복도 해당
- 함수적 종속성에 근거한 정규화 필요
- 함수의 종속성은 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭하는 것이다.
- 결정자 ex) 주민등록번호 // 종속자 ex) 이름, 출생지, 주소
- 정규화
- 1차 정규화 : 하나의 속성이 한 개의 속성값을 갖도록 한다.
- 2차 정규화 : 부분 함수 종속성을 제거한다. 1차 정규화 결과로 기본키가 하나라면 생략한다.
- 3차 정규화 : 이행 함수 종속성을 제거한다. 기본키를 제외한 속성 중 종속성이 발생하는 것을 제거한다.
- A→B→C 일 때, A→C가 되는 것을 제거하여 A→B, B→C로 테이블 분리
제 3절 반정규화와 성능
더보기
- 반정규화를 통한 성능향상전략
- 반정규화의 정의 : 정규화된 엔티티, 속성, 관계에 대해 시스템의 성능향상과 개발과 운영의 단순화를 위해 중복, 통합, 분리 등을 수행하는 데이터 모델링 기법
- 반정규화가 필요한 상황 : 대량 디스크 I/O, 조인으로 인한 성능저하, column 계산으로 인한 성능저하
- 반정규화 적용 방법 : 반정규화 대상 조사, 다른 방법 유도 검토, 반정규화 적용
- sorting과 ORDER BY는 반정규화의 대상이 아니다.
- 반정규화 기법
- 테이블 반정규화 : 테이블 병합, 테이블 분할, 테이블 추가
- 칼럼 반정규화 : 중복 칼럼 추가, 파생 칼럼 추가, 이력 테이블 칼럼 추가, PK에 의한 칼럼 추가, 응용시스템 오작동을 위한 칼럼 추가
- 관계 반정규화 : 중복 관계 추가
제 4절 대량데이터에 따른 성능
더보기
- 대량 데이터 발생에 따른 테이블 분할 개요
- 로우 체이닝(Row Chaining) : 로우 길이가 너무 길어서 데이터 블록 하나에 데이터가 모두 저장되지 않고 두개 이상 저장
- 로우 마이그레이션(Row Migration) : 데이터 블록에서 수정이 발생하면 수정된 데이터를 해당 데이터 블록에서 저장하지 못하고 다른 블록의 빈 공간을 찾아 저장하는 방식
- 한 테이블에 많은 수의 칼럼을 갖고있는 경우
- 대량 데이터 저장 및 처리로 인한 성능
- RANGE PARTITION 적용
- LIST PARTITION 적용
- HASH PARTITION 적용
- 파티셔닝(Partitioning)
- 하나의 테이블에 많은 양의 데이터가 저장되면 인덱스를 추가하고 테이블을 몇개로 쪼개도 성능이 저하되는 경우가 많다.
- 논리적으로 하나의 테이블이지만 물리적으로 여러개의 테이블로 분리하여 데이터 엑세스 성능 향상 & 데이터 관리 방법 개선
- 방법
- RANGE : 관리가 쉽다. 가장 많이 쓰인다. 숫자값으로 분리한다.
- LIST : 대용량, 특정 칼럼이 없을 때, PK
- HASH : 관리가 어렵다. 데이터 위치를 모를 때 사용한다.
제 5절 데이터베이스 구조와 성능
더보기
- 슈퍼타입 / 서브타입 모델의 성능 고려 방법
- 공통은 슈퍼타입으로 모델링하고, 공통으로부터 상속받아 다른 엔티티와 차이가 있는 속성은 별도의 서브엔티티 구분
- 슈퍼타입 모델링
- 장점 : 전체 검색이 쉽다. 무결성에 강하다.
- 단점 : 세부 속성이 많으면 NULL값이 많아 공간이 낭비된다.
- 서브타입 모델링
- 장점 : 공간 낭비가 줄고, 타입을 별개로 처리할 때 효율적이다.
- 단점 : UNION할 때 중복값이 제거되므로 PK 관리가 중요하다. INTERSECT 연산시 중복자원이 나오지 않도록 무결성 관리. 비효율적인 조인이나 집합 연산으로 성능이 저하될 수 있다.
- 인덱스 특성을 고려한 PK/FK 데이터 베이스 성능 향상
- PK 에서 앞쪽에 위치한 속성값이 가급적 = 아니면 최소한 범위 BETWEEN, <>이 들어와야 함
- PK 순서를 인덱스 특징에 맞게 고려하지 않고 바로 생성하게 되면 트랜잭션의 특징에 효율적이지 않은 인덱그 생성 ⇒ 인덱스 범위를 넓게 이용하거나 full scan 유발로 성능 저하
- 물리적인 테이블에 FK 제약이 걸려있지 않을 경우 인덱스 미생성으로 성능저하
- 물리적인 테이블에 FK 제약을 걸었을 때는 반드시 FK 인덱스를 생성하도록 하고 제약이 걸리지 않았을 때는 FK 인덱스를 생성하는 것을 기본 정책으로 하되, 거의 활용되지 않았을 때만 인덱스 지우기
제 6절 분산데이터베이스와 성능
더보기
- 분산데이터베이스의 개요 : 데이터베이스를 연결하는 빠른 네트워크 환경을 이용해 데이터베이스를 여러 지역 여러 노드로 위치시켜 사용성/성능 등을 극대화시킨 데이터베이스
- 분산데이터베이스의 투명성 : 분할, 위치, 지역 사상, 중복, 장애, 병행
- 분산데이터베이스의 특징
- 장점
- 지역 자치성, 점증적 시스템 용량 확장
- 신뢰성과 가용성
- 효용성과 융통성
- 빠른 응답 속도와 통신비용 절감
- 데이터 가용성과 신뢰성 증가
- 각 지역 사용자의 요구 수용 증대
- 단점
- 소프트웨어 개발 비용
- 오류의 잠재성 증대
- 처리 비용 증대
- 설계, 관리 복잡성과 비용
- 불규칙한 응답 속도
- 통제의 어려움
- 데이터 무결성 위협
- 장점
- 분산데이터베이스 설계가 효과적인 상황
- 성능이 중요한 사이트
- 공통코드, 기준정보, 마스터 데이터에 대해
- 실시간 동기화가 요구되지 않을 때 (거의 실시간일 때도 가능하다)
- 특정 서버에 부하가 집중될 때
- 백업 사이트를 구성할 때
제 3장 SQL 기본
제 1절 관계형 데이터베이스 개요
더보기
- SQL : 관계형데이터베이스에서 데이터 정의, 조작, 제어를 하기위해 사용하는 언어
- 데이터 조작어 (DML : Data Manipulation Language)
- SELECT, INSERT, UPDATE, DELETE
- 호스트 프로그램 속에 삽입되어 사용되는 DML 명령어들을 데이터 부속어(Data Sub Language)라고 한다.
- 데이터 정의어 (DDL : Data Definition Language)
- CREATE, ALTER, DROP, RENAME, TRUNCATE
- 데이터 제어어 (DCL : Data Control Language)
- GRANT, REVOKE
- 트랜잭션 제어어 (TCL : Transaction Control Language)
- COMMIT, ROLLBACK
- 데이터 조작어 (DML : Data Manipulation Language)
- TABLE : 테이블은 하나 이상의 칼럼을 가져야 한다.
- ERD(Entity Relationship Diagram) : 관계의 의미를 직관적으로 표현할 수 있는 수단. 엔티티, 관계 속성으로 구성된다.
제 2절 DDL
더보기
- 데이터 유형
- CHARACTER(s)
- 고정 길이 문자열 정보 (Oracle, SQL Server 모두 CHAR로 표현)
- s는 기본 길이 1바이트, 최대 길이 Oracle 2000, SQL Server 8000바이트
- 할당된 변수 값의 길이가 s보다 작을 경우에 그 차이만큼 공간으로 채운다.
- VARCHAR(s)
- 가변 길이 문자열 정보 (Oracle은 VARCHAR2, SQL Server는 VARCHAR로 표현)
- s는 최소 길이 1바이트, 최대 길이 Oracle 4000, SQL Server 8000바이트
- s만큼의 최대 길이를 갖지만 가변 길이로 조정되기 때문에 할당된 변수값의 바이트만 적용
- 문자 타입과 숫자 타입은 서로 반대로 입력이 가능하다. (자동 형변환)
- NUMERIC
- 정수, 실수 등 숫자 정보(Oracle은 NUMBER, SQL Server는 10가지 이상 숫자 타입 존재)
- Oracle은 처음에 전체 자리 수를 지정하고, 그 다음 소수 부분의 자리 수를 지정한다.
- ex) NUMBER(8, 2) : 정수 6자리, 소수 2자리
- DATETIME
- 날짜와 시각 정보(Oracle은 DATE 표현 & 1초 단위, SQL Server는 DATETIME 표현 & 3.33ms 단위)
- DATE에 문자열로 ‘2014-01-01’ 입력이 가능하다.
- 숫자는 불가능하다.
- IDENTITY(SQL Server)
- 자동 증가열
- IDENTITY (1, 1)은 1부터 시작해서 1씩 증가한다는 뜻이다.
- IDENTITY 칼럼에 값을 넣으면 에러가 발생한다.
- CHECK(Oracle)
- NULL을 넣으면 Error를 무시한다.
- CHARACTER(s)
- 명령어
- CREATE TABLE(칼럼명1 DATATYPE [DEFAULT 형식],
- 제약 조건 (CONSTRAINT)
- 사용자가 원하는 조건의 데이터만 유지하기 위한 방법
- PRIMARY KEY, UNIQUE KEY, NOT NULL, CHECK, FOREIGN KEY
- 제약 조건 (CONSTRAINT)
- 칼럼명2, DATATYPE [DEFAULT 형식);
- ⇒ CREATE TABLE 테이블 이름
- ALTER TABLE⇒ ALTER TABLE 테이블이름 ALTER 속성이름 [SET DEFAULT]; // 속성명 변경
- DROP COLUMN : 데이터가 있거나 없거나 상관없이 모두 삭제 가능, 한 번에 하나의 칼럼만 삭제가능
- MODIFY COLUMN, RENAME COLUMN
- DROP CONSTRAINT : 테이블 생성시 부여했던 제약조건을 삭제하는 명령어
- ADD CONSTRAINT : 테이블 생성 이후에 필요에 의해서 제약조건을 추가
- ⇒ ALTER TABLE 테이블이름 DROP 속성이름 [CASCADE | RESTRICT]; // 속성 삭제
- ⇒ ALTER TABLE 테이블이름 ADD 속성이름 데이터타입 [DEFAULT]; // 추가
- RENAME TABLERENAME COLUMN 변경해야할_컬럼명 TO 새로운_컬럼명;
- ⇒ ALTER TABLE 테이블이름
- DROP TABLE
- 테이블의 모든 데이터 및 구조 삭제
- CASECADE CONSTRAINT 옵션은 해당 테이블과 관계가 있었던 참조되는 제약 조건에 대해서도 삭제한다는 뜻
- ROLLBACK 불가능
- ⇒ DROP TABLE 테이블명;
- TRUNCATE TABLE
- 테이블 자체가 아닌 데이터만 제거
- 기존에 사용하던 테이블의 모든 로우를 제거하기 위한 명령어
- ⇒ TRUNCATE TABLE 테이블명;
- CREATE TABLE(칼럼명1 DATATYPE [DEFAULT 형식],
- CONSTRAINT
- 종류 : PK, FK, UNIQUE, NOT NULL, CHECK
- UNIQUE : 테이블 내에서 중복 값 x, NULL 입력 가능
- FK
- 테이블 생성시 설정 가능
- NULL 가능
- 한 테이블에 여러개 가능
- 참조 무결성 제약을 받을 수 있다.
- CHECK : 데이터베이스에서 데이터의 무결성을 유지하기 위해 테이블의 특정 column에 설정하는 제약
- PK : 반드시 한 테이블 당 하나의 제약만을 정의할 수 있다.
- FK 조건 (Delete / Modify 옵션)
- ON DELETE {OPTION} (default : NO ACTION)
- CASCADE : 부모 삭제시 자식도 삭제
- SET NULL, DEFAULT : 부모 삭제시 자식의 해당 필드 NULL, DEFAULT값으로 변경
- RESTRICT : 자식 테이블에 PK값이 없는 경우에만 부모 삭제 허용
- NO ACTION : 참조 무결성을 위반하는 삭제/수정 액션을 취하지 않음
- FK 조건(Insert 옵션)
- AUTOMATIC : 부모 PK가 없는 경우 부모 PK를 생성 후 자식 입력
- SET NULL : 부모 PK가 없는 경우 NULL
- SET DEFAULT : 부모 PK가 없는 경우 DEFAULT 값
- DEPENDENT : 부모 PK가 존재할 때만 자식 입력 허용
- NO ACTION : 참조 무결성을 위반하는 입력 액션을 취하지 않음
- 삭제 명령어 구분
| DROP | TRUNCATE | DELETE |
| DDL | DDL (일부 DML 성격) |
DML |
| Auto Commit | Auto Commit | 사용자 Commit |
| storage 모두 release | 최초 테이블 생성시 할당된 storage만 남기고 release | storage release X |
| UNDO를 위한 데이터를 생성하지 않기 때문에 동일 데이터량 삭제시 DELETE 보다 빠름 |
제 3절 DML
더보기
- INSERT⇒ INSERT INFO VALUES(전체_VALUES);
- ⇒ INSERT INTO 테이블명 (COLUMN_LIST) VALUES (VALUE_LIST);
- UPDATE
- ⇒ UPDATE 테이블명 SET 수정되는_컬럼명 = 새로운값;
- DELETE⇒ DELETE FROM 테이블명; // 전체 테이블 삭제
- ⇒ DELETE FROM 테이블명 WHERE 조건절;
- SELECT⇒ SELECT DISTINCT 칼럼명 FROM 테이블; // 중복 데이터 1건으로 표시
- ⇒ SELECT 칼럼명 FROM 테이블;
- 산술 연산자와 합성 연산자
- 우선순위를 위한 괄호 적용 가능
- 산술연산을 사용하거나 특정 함수를 적용하게 되면 적절한 ALIAS를 사용하는 것이 좋다.
SELECT PLAYER_NAME || ‘선수’, || HEIGHT || ‘cm’ || WEIGHT || ‘kg’ 체격정보 FROM PLAYER;
⇒ SQL Server
제 4절 TCL
더보기
- 트랜잭션 개요
- 데이터베이스의 논리적 연산 단위
- 분리될 수 없는 한 개 이상의 데이터 베이스 조작을 가리켜 하나의 트랜잭션에는 하나 이상의 SQL문장이 포함
- 분리될 수 없는 최소의 단위 (전부 적용하거나 전부 취소. 원자성)
- 트랜잭션의 특성 : 원자성, 일관성, 고립성, 지속성
- 원자성 : 트랜잭션에서 정의된 연산들은 모두 성공하던지 아니면 전혀 실행되지 않은 상태여야 한다.
- 일관성 : 트랜잭션이 실행되기 전 데이터베이스 내용이 잘못되지 않다면 이후에도 잘못이 있으면 안된다.
- 고립성 : 트랜잭션 실행 도중 다른 트랜잭션의 영향을 받아 잘못된 결과를 만들어서는 안된다.
- 지속성 : 트랜잭션이 성공적으로 실행되면 갱신된 내용은 영구적으로 저장된다.
- COMMIT
- Oracle은 DML 후 COMMIT, ROLLBACK 해줘야 함
- SQL Server는 AUTO COMMIT
- Oracle은 DDL AUTO COMMIT
- SQL Server는 사용자가 COMMIT, ROLLBACK
- 문법
=> Oracle
UPDATE ...;
COMMIT;
=>SQL
UPDATE;
- ROLLBACK
- 문법
=> Oracle
UPDATE ... ;
ROLLBACK;
=> SQL
BEGIN TRAN UPDATE ...;
ROLLBACK;
- 문법
- SAVEPOINT
- 현 시점에서 SAVEPOINT까지 트랜잭션의 일부만 롤백할 수 있다.
- 문법
=> SQL
SAVEPOINT 세이브포인트명
ROLLBACK TO 세이브포인트명;
제 5절 WHERE절
더보기
- WHERE 조건절 개요 : 자신이 원하는 자료만을 검색하기 위해 이용
- 괄호로 묶은 연산이 제일 먼저 연산 처리
- 부정 연산자가 가장 먼저 처리
- 비교 연산자가 그 다음으로 처리
- 논리 연산자는 AND → OR
- ⇒ WHERE [DISTINCT/ALL] 칼럼명 [ALIAS명] FROM 테이블명 WHERE 조건식;
- 연산자 종류 : 비교 연산자, SQL 연산자, 논리 연산자, 부정 비교 연산자, 부정 SQL 연산자
- 비교 연산자 : =, >, ≥, <, ≤
- SQL (부정) 연산자 : (NOT) BETWEEN a AND b, (NOT) IN (list), LIKE ‘비교문자열’, IS (NOT) NULL
- NULL 값과의 수치연산은 NULL값을 리턴한다.
- NULL 값과의 비교연산은 FALSE를 리턴한다.
- NOT IN에서 NULL은 True를 리턴한다.
- IN(NULL)은 공집합을 리턴한다.
- IN 절은 중복이 제거되어 조건을 만족하는 결과를 리턴한다.
- 논리 연산자 : AND, OR, NOT
- 부정 비교 연산자 : ≠, ^=, <>, NOT 칼럼명 = , NOT 칼럼명 > (~보다 크지 않다)
- ROWNUM & TOP
- SQL 처리 결과 집합의 각 행에 대해 임시로 부여되는 일련번호
- Oracle - ROWNUM
- WHERE 절에서 행의 개수를 제한하는 목적으로 사용
- SQL - TOP
- Expression : 반환할 행의 수를 지정하는 숫자
- PERCENT : 쿼리 결과 집합에서 처음 Expression 의 행만 반환
- WITH TIES : ORDER BY 절이 지정된 경우에만 사용 가능. 마지막 행과 같은 값이 있는 경우 추가 행이 출력되도록 지정
- iiii. ORDER BY 절이 사용되지 않으면 ROWNUM과 같은 기능을 한다.
제 6절 함수
더보기
- 내장 함수 개요 : 함수는 입력되는 값이 많아도 출력은 하나만 된다. (M:1)
- LTRIM(‘xxxYYZZxYZ’, ‘x’) ⇒ ‘YYZZxYZ’
- RTRIM(‘XXYYzzXYzz’, ‘z’) ⇒ ‘XXYYzzXY’
- TRIM(‘x’ FROM ‘xxYYZZxYZxx’) ⇒ ‘YYZZxYZ’
- RTRIM(‘XXYY ‘) ⇒ ‘XXYY’
- 공백제거 및 CHAR과 VARCHAR 데이터 유형을 비교할 때 용이하게 사용
- 숫자형 함수
- TRUNC(숫자, [m]) : 숫자를 m자리에서 잘라서 버린다.
- 날짜형 함수
- SYSDATE(Oracle), GETDATE()(SQL Server) : 현재 날짜, 시각
- EXTRACT(‘YEAR’|’MONTH’|’DAY’ form d) / DATEPART(‘YEAR’|’MONTH’|’DAY’ form d) : 날짜 데이터에서 년/월/일 데이터 출력. 시간/분/초 가능
- TO_NUMBER(TO_CHAR(d, ‘YYYY’)) / YEAR, MONTH, DAY(d): 년/월/일 추출. TO_NUMBER 제외 시 문자형으로 출력
- 변환형 함수
- 데이터 유형 변환의 종류
- 명시적(Explicit) 데이터 유형 변환 : 데이터 변환형 함수로 데이터 유형을 변환하도록 명시해 주는 경우
- 암시적(Implicit) 데이터 유형 변환 : 데이터베이스가 자동으로 데이터 유형을 변환하여 계산하는 경우
- 단일행 변환형 함수의 종류
- Oracle : TO_NUMBER(), TO_CHAR(), TO_DATE()
- SQL Server : CAST(expression AS data_type [(length)]), CONVERT(data_type [(length)], expression, [style])
- 데이터 유형 변환의 종류
- CASE 표현
- IF-THEN-ELSE 와 유사
- CASE WHEN A THEN B WHEN C THEN D ELSE E END
- ⇒ SELECT ENAME, CASE WHEN SAL≥3000 THEN ‘HIGH’ WHEN SAL≥1000 THEN ‘MID’ ELSE ‘LOW’ END AS SALARY_GRADE FROM EMP;
- NULL 관련 함수
- NVL, ISNULL
- NULLIF
- COALESCE
- DECODE
- 조건에 맞는 데이터가 한 건도 없는 경우 공집합이라고 하고, NULL과는 다르다
제 7절 GROUP BY, HAVING 절
더보기
- 집계 함수
- 여러 행들의 그룹이 모여서 그룹 당, 단 하나의 결과를 돌려주는 다중행 함수 중 하나
- GROUP BY 절은 행들을 소그룹화 한다.
- SELECT, HAVING, ORDER BY 절에 사용할 수 있다.
- GROUP BY 절과 함께한다면 ORDER BY 절에 집계 함수를 사용할 수 있다.
- WHERE 절에는 사용할 수 없다.
- SUM, AVG, MAX, MIN, STDDEV, VARIAN([DISTINCT|ALL] 표현식)
- HAVING
- WHERE 절과 비슷하지만 그룹을 나타내는 결과 집합의 행에 조건이 적용된다.
- CASE 표현을 활용한 월별 데이터 집계
- “집계함수( CASE()) ~ GROUP BY” 기능은 모델링의 제1 정규화로 인해 반복되는 경우 구분 칼럼을 두고 여러 개의 레코드로 만들어진 집합을, 정해진 칼럼 수만큼 확장해서 집계 보고서를 만드는 유용한 기법이다.
- 집계함수와 NULL 처리
- NULL이 아닌 0을 표시하고 싶은 경우에는 NVL(SUM(SAL), 0)이나, ISNULL(SUM(SAL, 0) 처럼 SUM의 결과가 NULL인 경우( 대상 건수가 모두 NULL인 경우)에만 한 번 NVL/ISNULL을 사용하면 된다.
제 8절 ORDER BY
더보기
- ORDER BY
- ORDER BY 절에 칼럼명 대신에 SELECT 절에서 사용한 ALIAS 명이나 칼럼 순서를 나타내는 정수도 사용 가능
- SELECT 문장 실행 순서
- FROM → WHERE → GROUP BY → HAVING → SELECT → ORDER BY
- 따라서 SELECT에 명시되지 않은 칼럼은 ORDER BY절에서 사용할 수 없다.
- Oracle에서 논리적으로 맞지는 않지만 GROUP BY를 사용하지 않았다면 오류는 나지 않는다.
- TOP N 쿼리
제 9절 조인
더보기
- EQUI JOIN
- 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하는 경우에 사용되는 방법
- 대부분 PK↔FK 관계를 기반으로 한다. 그러나 반드시는 아님⇒ SELECT PLAYER.PLAYER_NAME, TEAM.TEAM_NAME FROM PLAYER INNER JOIN TEAM ON PLAYER.TEAM_ID = TEAM.TEAM_ID;
- ⇒ SELECT PLAYER.PLAYER_NAME, TEAM.TEAM_NAME FROM PLAYER, TEAM WHERE PLAYER.TEAM_ID = TEAM.TEAM_ID;
- Non EQUI JOIN
- 두 개의 테이블 간에 칼럼 값들이 서로 정확하게 일치하지 않는 경우에 사용된다.
- BETWEEN, >, ≥, <, ≤ 등의 연산자들을 사용하여 JOIN
제 4장 SQL 활용
제 1절 표준 조인
더보기
- STANDARD SQL
- 일반 집합 연산자 → SQL
- UNION → UNION
- INTERSECTION → INTERSECT
- DEFFERENCE → EXCEPT(Oracle : MINUS)
- PRODUCT → CROSS JOIN(CARTESIAN PRODUCT)
- 순수 관계 연산자 → SQL
- SELECT → WHERE
- PROJECT → SELECT
- (NATURAL) JOIN → 다양한 JOIN
- DIVIED → 현재 사용하지 않음
- 일반 집합 연산자 → SQL
- FROM 절과 JOIN 형태 : INNER JOIN, NATURAL JOIN, USING 조건절, ON 조건절, CROSS JOIN, OUTER JOIN
- INNER JOIN
- JOIN 조건에서 동일한 값이 있는 행만 반환
- DEFAULT 옵션이므로 생략 가능
- CROSS, OUTER JOIN과는 같이 사용할 수 없음
- USING이나 ON 조건절을 필수적으로 사용
- ⇒ SELECT PLAYER.PLAYER_NAME, TEAM.TEAM_NAME FROM PLAYER INNER JOIN TEAM ONPLAYER.TEAM_ID = TEAM.TEAM_ID;
- NATURAL JOIN
- 두 테이블 간의 동일한 이름을 갖는 모든 칼럼에 대해 EQUI JOIN을 수행
- 추가로 USING, ON, WHERE 절에서 JOIN 조건을 정의할 수 없음
- JOIN에 사용된 칼럼들은 같은 데이터 유형이어야 한다.
- ALIAS나 테이블명과 같은 접두사를 붙일 수 없다.
- USING 조건절
- 같은 이름을 가진 칼럼들 중에서 원하는 칼럼에 대해서만 선택적으로 EQUI JOIN을 할 수 있다.
- SQL Server에서는 지원하지 않는다.
- JOIN 칼럼에 대해서 ALIAS나 테이블명과 같은 접두사를 붙일 수 없다.
- SELECT * FROM PLAYER JOIN TEAM USING (TEAM_NAME);
- ON 조건절
- 칼럼명이 다르더라도 JOIN 조건을 사용할 수 있는 장점이 있다.
- WHERE 검색 조건은 충돌없이 사용할 수 있다.
- ON 조건절에서 사용된 괄호는 옵션사항이다.
- ALIAS나 테이블명과 같은 접두사를 사용해야 한다.
- CROSS JOIN
- CARTESIAN PRODUCT : JOIN 조건이 없는 경우 생길 수 있는 모든 데이터의 조합
- OUTER JOIN
- JOIN 조건에서 동일한 값이 없는 행도(NULL 값도) 출력된다.
- USING 조건 절이나 ON 조건 절을 필수적으로 사용해야 한다.
- LEFT OUTER, RIGHT OUTER, FULL OUTER
- Oracle에서 WHErE A.col1 = B.col2(+) ⇒ A LEFT OUTER JOIN B이다.
제 2절 집합 연산자
더보기
- 집합 연산자 개요
- 두 개 이상의 테이블에서 조인을 사용하지 않고 연관된 데이터를 조회하는 방법 중 하나
- 집합 연산자는 2개 이상의 질의 결과를 하나의 결과로 만들어준다.
- SELECT 절의 칼럼 수가 동일하고 동일 위치에 존재하는 칼럼의 데이터 타입이 상호 호환 가능해야 한다.
- UNION, UNION ALL, INTERSECT, EXCEPT(MINUS)
제 3절 계층형 질의와 셀프 조인
더보기
- 계층형 질의
- 테이블에 계층형 데이터가 존재하는 경우 데이터를 조회하기 위해서 계층형 질의(Hierarchical Query)를 사용한다.
- 엔티티를 순환관계 데이터 모델로 설계할 경우 계층형 데이터가 발생한다. (ex. 조직, 사원, 메뉴 등)
- Oracle 계층형 질의START WITH condition[ORDER SIBLINGS BY column, column, … ]
- PRIOR : CONNECT BY 절에 사용되며 현재 읽은 칼럼을 지정한다. PRIOR 자식 = 부모 를 사용하면 부모→자식 방향으로 전개한다. SELECT, WHERE 절에도 사용이 가능하다.
- LEVEL : 루트 데이터는 1, 리프 데이터까지 1씩 증가
- CONNECT_BY_ISLEAF : 전개 과정에서 해당 데이터가 리프 데이터이면 1, 그렇지 않으면 0이다.
- CONNECT_BY_ISCYCLE : 전개 과정에서 지식을 갖는데, 해당 데이터가 조상으로서 존재하면 1, 그렇지 않으면 0이다. CYCLE 옵션을 사용했을 때만 사용할 수 있다.
- CONNECT BY [NOCYCLE] condition AND condition…
- ⇒ SELECT … FROM 테이블 WHERE condition AND condition…
- SQL Server 계층형 질의
- CTE(Common Table Expression)를 재귀 호출
- 앵커 멤버가 시작점이자 Outer 집합이 되어 Inner 집합인 재귀 멤버와 조인 시작 → 앞서 조인한 결과가 다시 Outer 집합이 되어 재귀 반복 → 조인 결과가 비어있어 더 조인할 수 없으면 지금까지 만들어진 결과 집합을 모두 합하여 리턴
- 셀프 조인
- 동일 테이블 사이의 조인
- 반드시 ALIAS를 사용해야 한다.
제 4절 서브 쿼리
더보기
- 서브 쿼리 개요
- 하나의 SQL문 안에 포함되어있는 또다른 SQL문
- 서브 쿼리는 메인 쿼리의 칼럼을 모두 사용할 수 있지만, 메인 쿼리는 서브 쿼리의 칼럼을 사용할 수 없다.
- 사용하기 위해서는 스칼라 서브쿼리, 조인, 함수를 사용해야한다.
- 서브 쿼리는 괄호로 감싸서 사용한다.
- 단일행 또는 복수행 비교연산자와 함께 사용 가능하다.
- ORDER BY를 사용하지 못한다.
- SELECT, FROM, HAVING, ORDER BY 절에 사용할 수 있다.
- 서브 쿼리 분류
- 동작 방식에 따른 분류
- 비연관 서브 쿼리 : 서브 쿼리가 메인 쿼리 칼럼을 갖고있지 않은 형태의 서브 쿼리. 메인 쿼리에 서브 쿼리가 실행된 결과를 제공하기 위해 주로 사용한다.
- 연관 서브 쿼리 : 서브 쿼리가 메인 쿼리 칼럼을 갖고있는 형태의 서브쿼리이다. 일반적으로 메인 쿼리가 먼저 수행되어 읽혀진 데이터를 서브 쿼리에서 조건이 맞는지 확인하고자 할 때 주로 사용한다.
- 반환되는 데이터의 형태에 따른 분류
- 단일행 서브쿼리 : 서브 쿼리 실행 결과가 1건 이하. 단일행 비교 연산자와 함께 사용된다.
- 다중행 서브쿼리 : 다중행 비교 연산자(IN, ALL, ANY, SOME, EXISTS)와 함께 사용된다.
- (비교연산자) ALL (서브쿼리) : 서브쿼리의 결과에 존재하는 모든 값을 만족하는 조건. 비교연산자가 > 라면 서브쿼리의 최대값보다 큰 모든 건
- (비교연산자) ANY/SOME (서브쿼리) : 서브쿼리의 어떤 값이라도 만족하면 됨. 비교연산자가 > 라면 서브쿼리의 최소값보다 큰 모든 건
- EXISTS는 항상 연관서브쿼리로 사용
- 다중행 서브쿼리의 비교연산자는 단일행 서브쿼리의 비교연산자로 사용할 수 있다. M:M
- 다중 칼럼 서브 쿼리 : 메인 쿼리의 조건절에 여러 칼럼을 동시에 비교할 수 있다. 비교하고자 하는 칼럼 개수와 위치가 동일해야 한다.
- 동작 방식에 따른 분류
- 기타 서브 쿼리
- SELECT 절에 서브 쿼리 → 스칼라 서브 쿼리
- ⇒ SELECT. … , (SELECT AVG(HEIGHT) FROM …) FROM … ;
- FROM 절에 서브 쿼리 → 인라인뷰(Inline View), 동적뷰(Dynamic View)라고도 한다.
- 인라인뷰에서는 ORDER BY절을 사용할 수 있다.
- 인라인뷰에 먼저 정렬을 수행하고 정렬된 결과 중에서 일부데이터를 추출하는 것을 TOP-N 쿼리라고 한다.
- SQL 문장 중 테이블 명이 올 수 있는 곳에서 사용할 수 있다.
- 인라인 서브쿼리의 칼럼은 메인쿼리에서 사용할 수 있다.
- HAVING 절에 서브 쿼리
- UPDATE 문의 SET에서 사용
- INSERT 문의 VALUES절에서 사용
- ORDER BY 절에서 사용
- 뷰(View)
- 테이블은 실제로 데이터를 갖고있는 반면, 뷰는 실제 데이터를 갖고있지 않다.
- 장점
- 독립성 : 테이블 구조가 변경되어도 뷰를 사용하는 응용 프로그램은 변경하지 않아도 된다.
- 편리성 : 복잡한 질의를 뷰로 생성함으로써 관련 질의를 단순하게 작성할 수 있다. 또한 해당 형태의 SQL문을 자주 사용할 때 뷰를 이용하면 편리하게 사용할 수 있다.
- 보안성 : 직원의 급여정보와 같이 숨기고 싶은 정보가 존재한다면, 뷰를 생성할 떄 해당 칼럼을 빼고 생성함으로써 사용자에게 정보를 감출 수 있다.
제 5절 그룹 함수
더보기
- 데이터 분석 개요
- ANSI/ISO SQL 표준은 데이터 분석을 위해서 다음 세가지 함수를 정의하고 있다.
- AGGREGATE FUNCTION, GROUP FUNCTION, WINDOW FUNCTION
- ROLLUP
- Grouping Columns의 수를 N이라고 했을 때 N+1 Level의 Subtotal이 생성된다.
- 계층 구조이므로 인수 순서가 바뀌면 수행 결과도 바뀜. 가능한 Subtotal만 생성
- CUBE
- 결합 가능한 모든 값에 대해 다차원 집계 생성
- GROUPING SETS
- 원하는 부분의 소계만 손쉽게 추출할 수 있다.
- 인수는 평등한 관계이므로 인수의 순서가 바뀌어도 결과는 같다.
제 6절 윈도우 함수
더보기
- WINDOW FUNCTION 개요
- OVER 문구가 키워드로 필수 포함된다.
- 분석함수, 순위함수
- GROUP BY 절과 Window Function은 병행하여 사용할 수 없다.
- 윈도우 함수 처리로 인해 결과 건수는 줄어들지 않는다.
- 윈도우 함수 적용 범위는 partition을 넘지 않는다.
- 행-행 관계를 정의하는데 사용된다.
- WINDOWING 함수 2가지 종류 : BETWEEN 사용 타입, 미사용 타입
- 그룹 내 순위 함수
- RANK 함수
- DENSE_RANK 함수 : 동일한 순위를 하나의 건수로 취급. 중간 순위를 비우지 않음
- ROW_NUMBER 함수 : 동일한 값이라도 고유한 순위를 부여한다는 점이 RANK, DENSE_RANK와 다르다.
- 일반 집계 함수
- SUM, MAX, MIN, AVG, COUNT
- COUNT(*)에서 NULL인 것을 포함한다.
- SUM, MAX, MIN, AVG, COUNT
- 그룹 내 행 순서 함수
- FIRST_VALUE : 파티션별 윈도우에서 가장 먼저 나온 값
- LAST VALUE : 파티션별 윈도우에서 가장 나중에 나온 값
- LAG : 현재 읽혀진 데이터의 이전 값을 알아내는 함수
- LEAD : 이후 값을 알아내는 함수
- 그룹 내 비율 함수(SQL Server에서는 지원되지 않는다)
- RATIO_TO_REPORT : 전체 SUM(칼럼) 값에 대한 행별 칼럼 값의 백분율을 소수점으로 구함
- PERCENT_RANK : 제일 먼저 나오는 것을 0으로, 제일 늦게 나오는 것을 1로 하여, 값이 아닌 행의 순서별 백분율을 구함
- CUME_DIST : 전체건수에서 현재 행보다 작거나 같은 건수에 대한 누적 백분율⇒ DEPNO = 20에서 SCOTT와 FORD는 같은 ORDER를 가지기 때문에 둘을 합친 CUME_DIST를 갖는다
- NTILE : 전체 건수를 ARGUMENT 값으로 N등분한 결과⇒ 14개를 4개의 조로 나누면 14 = 3*4 + 2
- 나머지 2는 앞 조부터 순서대로 부여된다.
-
제 7절 DCL
더보기
- DCL 개요 : 유저를 생성하고 권한을 제어할 수 있는 DCL(Data Control Language) 명령어
- Oracle에서 제공하는 유저들
- SCOTT : 테스트용 샘플 유저. Default 패스워드 TIGER
- SYS : DBA ROLE을 부여받은 유저
- SYSTEM : 데이터베이스의 모든 시스템 권한을 부여받은 DBA 유저. Oracle 설치 완료 시에 패스워드 설정
- Oracle에서 제공하는 유저들
- 유저와 권한
- 유저 생성과 시스템 권한 부여 : ROLE을 이용해 간편하고 쉽게 권한 부여
- OBJECT에 대한 권한 부여 : 권한은 특정 오브젝트인 테이블, 뷰 등에 대한 SELECT, INSERT, DELETE, UPDATE 작업 명령어를 의미
- ROLE을 이용한 권한 부여
- 많은 데이터베이스에서 유저들과 권한들 사이에서 중개 역할을 하는 ROLE을 제공한다.
- 데이터 베이스 관리자는 ROLE을 생성하고, ROLE에 각종 권한들을 부여한 후 ROLE을 다른 ROLE이나 유저에게 부여할 수 있다.
- ROLE에 포함되어있는 권한들이 필요한 유저에게는 해당 ROLE만을 부여함으로써 빠르고 정확하게 필요한 권한을 부여
제 8절 절차형 SQL
더보기
- 절차형 SQL 개요
- SQL에도 절차 지향적인 프로그램이 가능하도록 DBMS 벤더 별로 PL/SQL(Oracle), SQL/PL(DB2), T-SQL(SQL Server) 등의 절차형 SQL을 제공하고 있다.
- 절차형 SQL을 이용하면 SQL문의 연속적인 실행이나 조건에 따른 분기처리를 이용하여 특정 기능을 수행하는 저장 모듈을 생성할 수 있다.
- PL/SQL 개요
- PL/SQL의 특징 : Oracle의 PL/SQL은 Block 구조로 되어있고 Block 내에는 DML 문장과 QUERY 문장, 그리고 절차형 언어(IF, LOOP) 등을 사용할 수 있으며, 절차적 프로그래밍을 가능하게 하는 트랜잭션 언어이다.
- 변수, 상수 등을 선언하여 일반 SQL 문장을 실행할 때 WHERE 절의 조건 등으로 대입 가능
- DBMS 정의 에러, 사용자 정의 에러 정의하여 사용 가능
- 응용 프로그램의 성능 향상
- 한 번에 Block전부를 서버로 보내기 때문에 통신량 감소
- DDL 명령어를 PL/SQL 내부에서 실행하기 위해 execute immediate를 붙여 dynamic 형태로 동작시킨다.
- T-SQL 개요
- T-SQL 특징 : T-SQL은 근본적으로 SQL Server를 제어하기 위한 언어로서, T-SQL은 엄격히 말하면 MS사에서 ANSI/ISO 표준의 SQL에 약간의 기능을 더 추가해 보완적으로 만든 것
- Procedure의 생성과 활용
- Procedure은 작성자의 기준으로 트랜젝션을 분할할 수 있다.
- Procedure 내에서 다른 Procedure를 호출할 때 호출 Procedure과는 별도로 PRAGMA AUTONOMOUS_TRANSACTION을 선언하여 자율 트랜잭션 처리를 할 수 있다.
- User Defined Function의 생성과 활용
- 절차형 SQL을 로직과 함께 데이터베이스 내에 저장해놓은 명령문의 집합을 의미한다.
- 한 번에 return 할 수 있는 결과 한 건 (없으면 NULL)
- 작성자 기준으로 트랜젝션을 분할할 수 있다.
- Trigger의 생성과 활용
- 데이터의 무결성과 일관성을 위해서 사용한다.
- 특정 테이블에 INSERT, UPDATE, DELETE와 같은 DML문이 수행되었을 때, 데이터베이스에서 자동으로 동작하도록 작성된 프로그램
- 즉 사용자가 직접 호출하는 것이 아니고 데이터베이스에 의해 자동적으로 수행한다.
- Trigger는 테이블과 뷰, 데이터베이스 작업을 대상으로 정의할 수 있으며, 전체 트랜잭션 작업에 대해 발생되는 Trigger와 각 행에 대해서 발생되는 Trigger가 있다.
- Trigger는 데이터베이스에 의해 자동 호출되지만 결국 INSERT, UPDATE, DELETE 문과 하나의 트랜잭션 안에서 일어나는 일련의 작업들이라 할 수 있다.
- Trigger는 데이터베이스 보안의 적용, 유효하지 않은 트랜잭션의 예방, 업무 규칙 자동 적용 제공 등에 사용될 수 있다.
- 데이터베이스에 로그인하는 작업에도 정의할 수 있다.
- Procedure과 Trigger의 차이
| Procedure | Trigger |
| CREATE Procedure | CREATE Trigger |
| EXECUTE 명령어로 실행 | 생성 후 자동으로 실행 |
| COMMIT, ROLLBACK과 같은 TCL 실행 가능 | TCL 실행 불가능 |
제 5장 SQL 최적화 기본원리
제 1절 옵티마이저와 실행 계획
더보기
- 옵티마이저
- 다양한 실행방법들 중에서 최적의 실행방법을 결정하는 것
- 규칙 기반 옵티마이저(RBO)
- row id > cluster join > hash with unique | pk
- 비용 기반 옵티마이저(CBO)
- 통계, DBMS 버전, 설정 정보 등의 차이로 인해 동일 SQL문도 서로 다른 실행계획이 생성될 수 있다.
- 다양한 한계로 인해 실행계획의 예측 및 제어가 어렵다는 단점이 있다.
- 옵티마이저 실행계획
- SQL에서 요구한 사항을 처리하기 위한 절차와 방법
- 실행 계획 구성 요소 : 조인 순서, 조인 기법, 액세스 기법, 최적화 정보, 연산 등
- 다양한 처리 방법(실행계획) 존재, 처리 방법마다 실행 시간(성능) 차이
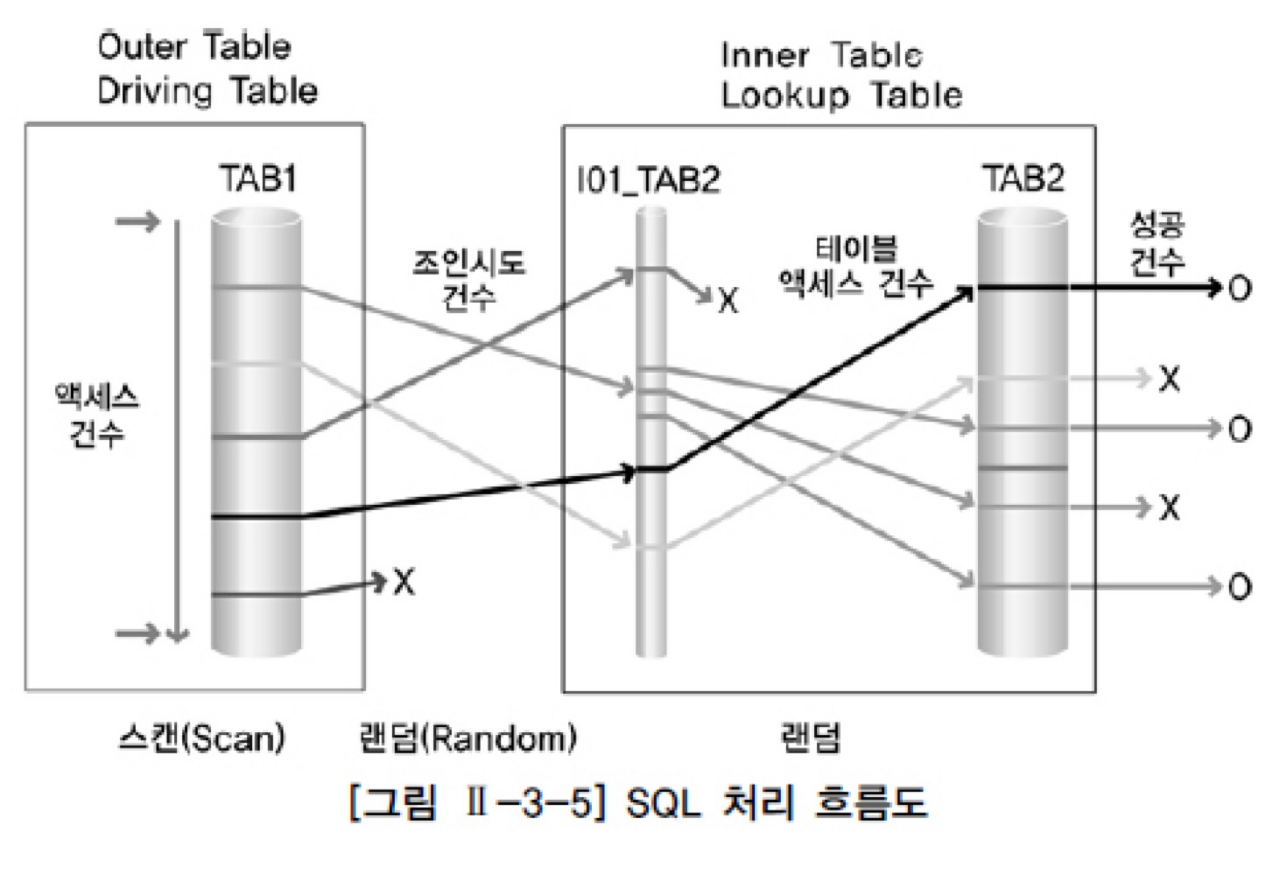
- SQL 처리 흐름도
- SQL의 내부적인 처리 절차를 시각적으로 표현한 도표
제 2절 인덱스 기본
더보기
- 인덱스 특징과 종류
- 원하는 데이터를 쉽게 찾을 수 있도록 돕는 기능
- DML 작업은 테이블과 인덱스를 함께 변경해야하기 때문에 느려질 수 있다.(UPDATE는 느려지지 않을 수도 있다.)
- 트리 기반 인덱스
- DBMS에서 가장 일반적인 인덱스는 B-TREE
- 리프 블록은 인덱스를 구성하는 칼럼의 데이터와 해당 데이터를 가지고 있는 행의 위치를 가리키는 레코드식별자(RID, Record Identifier / Rowid)로 구성되어있다.
- = 로 검색하는 일치 검색과 BETWEEN 등의 범위 검색 모두 적합
- SQL Server의 클러스터형 인덱스
- 클러스터형, 비클러스터형 인덱스
- 인덱스 리프페이지가 곧 데이터페이지
- 리프 페이지의 모든 로우는 인덱스 키칼람 순으로 물리적으로 정렬되어 저장
- Oracle의 IOT와 유사
- BITMAP 인덱스
- 시스템에서 사용될 질의를 시스템 구현시에 모두 알 수 없는 경우인 DW, AD-HOC 질의 환경을 위해 설계되었다.
- 하나의 인덱스 키 엔트리가 많은 행에 대한 포인터를 저장하고 있는 구조
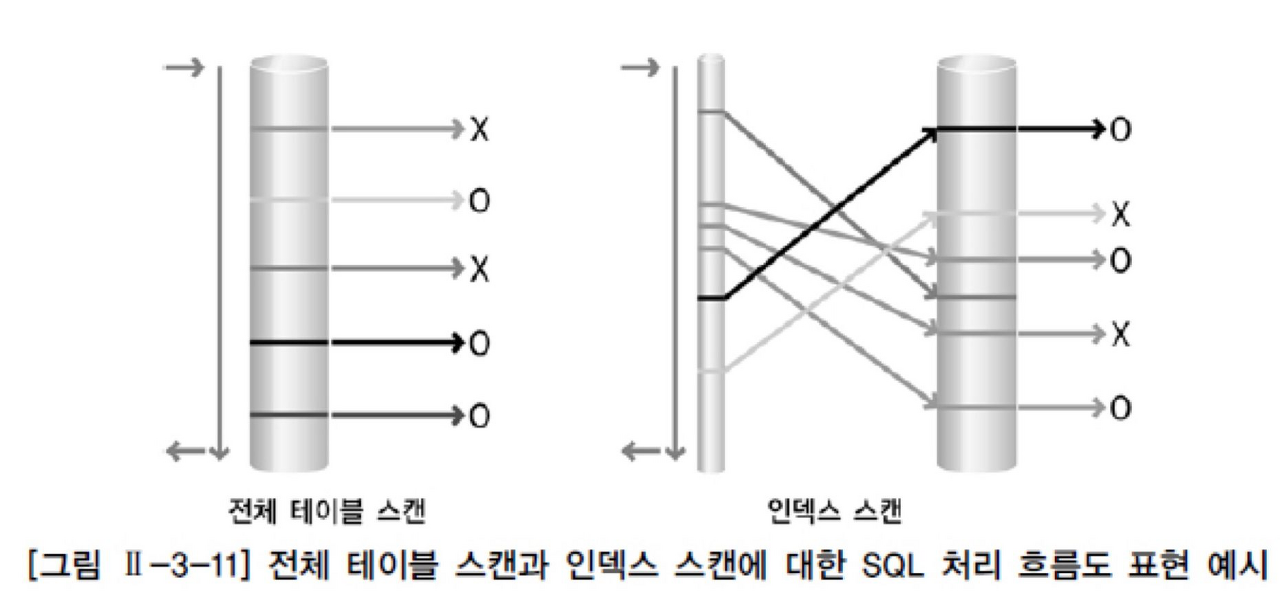
- 전체 테이블 스캔과 인덱스 스캔
- 전체 테이블 스캔
- 인덱스 스캔
- Unique Index Scan에서 PK가 두개 이상이라면 개수를 맞춰서 조건절에 모두 사용해서 비교해야한다.
- 비교
제 3절 조인 수행 원리
더보기
- NL JOIN
- 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 수행for(후행테이블/Inner table)
- ⇒ for(선행테이블/Outer table)
- 결과 행의 수가 적은 테이블을 조인 순서상 선행 테이블로 선택하는 것이 전체 일량을 줄임
- 조인이 성공하면 바로 조인 결과를 사용자에게 보여줌으로 온라인에 적당
- 랜덤 액세스
- 유니크 인덱스를 활용해 수행시간이 적게 걸리는 소량 테이블을 온라인 조회하는 경우 유용하다.
- Sort Merge JOIN
- 주로 스캔하는 방식
- 조인 칼럼 인덱스 없어도 사용가능 (성능이 떨어질 수 있음)
- 조인 칼럼 기준으로 데이터를 정렬하여 조인 수행
- NL JOIN에서 부담되던 넓은 범위의 데이터를 처리할 때 이용되던 조인기법
- 정렬 데이터가 많아 메모리에서 수행이 불가능하면 디스크를 사용해서 성능이 떨어질 수도 있다.
- Hash JOIN
- 조인을 수행할 테이블의 조인 칼럼을 기준으로 해쉬 함수 수행
- 조인 칼럼 인덱스 사용 x
- 서로 동일한 해쉬 값을 갖는 것들 사이에서 실제 값이 같은지 비교하면서 조인 수행
- NL JOIN의 랜덤 액세스와 SM JOIN의 문제점인 정렬 작업의 부담을 해결하기 위한 대안으로 등장
- EQUI JOIN에만 사용
- 결과 행의 수가 주 메모리의 가용 메모리에 충분히 담길만큼 작은 규모의 테이블을 선행 테이블로 사용하는 것이 좋다.
'기타' 카테고리의 다른 글
| 클린 아키텍쳐를 읽으면서 (0) | 2022.12.28 |
|---|